When interviewing a candidate, I usually ask them to tell me something about async/await as we know it in modern languages like C# or TypeScript. What does it do? Why do we use it? Most people talk about technical details and threads. Some of these details are correct, some are not. However, I have never heard anyone mention the problem that led to the inception of the async/await concept.
At university, one of the modules I studied was Parallel Algorithms. The module covered questions like, "What kind of problems can be solved more efficiently on multiple processors?" and "How can we design efficient parallel algorithms?" And the first lecture presented question: "Does the number of available processors impact the design of a parallel algorithm?" This question is very important because, when tasked with designing a parallel algorithm, we usually don't know how many processors will be available. The answer is "No." The number of processors does not impact the design of a parallel algorithm. How does that work? When designing a parallel algorithm, we split the computational work into small tasks. Unfortunately, those tasks may have dependencies on one another.
For example, consider an algorithm to sum the numbers in an array of length \(N\). The algorithm creates \(N\) tasks, and each task adds the value at a specific index to the result of the previous task, starting with the value at index 0: \(T(i) = T(i-1) + A[i]\) where \(T(0) = A[0]\). The final result is \(T(N-1)\). The problem is that each task depends on the previous one, so there are no two tasks that can run in parallel. The following image presents the tasks for an array of length 5. The arrows represent dependencies between tasks.
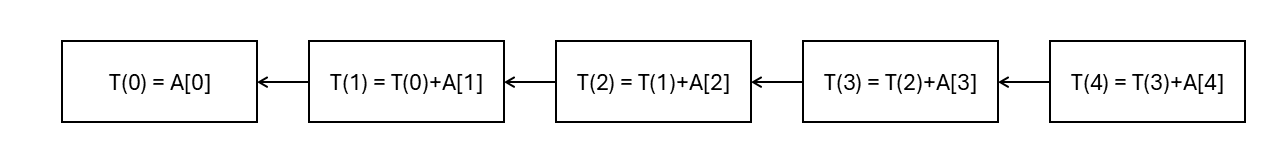
To take advantage of multiple processors, we need to change the dependencies between the tasks. We can do this by making the algorithm work in rounds. In the first round, each task adds two values from the array. In the second round, each task adds two values from the results of the previous round, and so on. The following image presents the tasks for an array of length 10. The arrows represent dependencies between tasks.
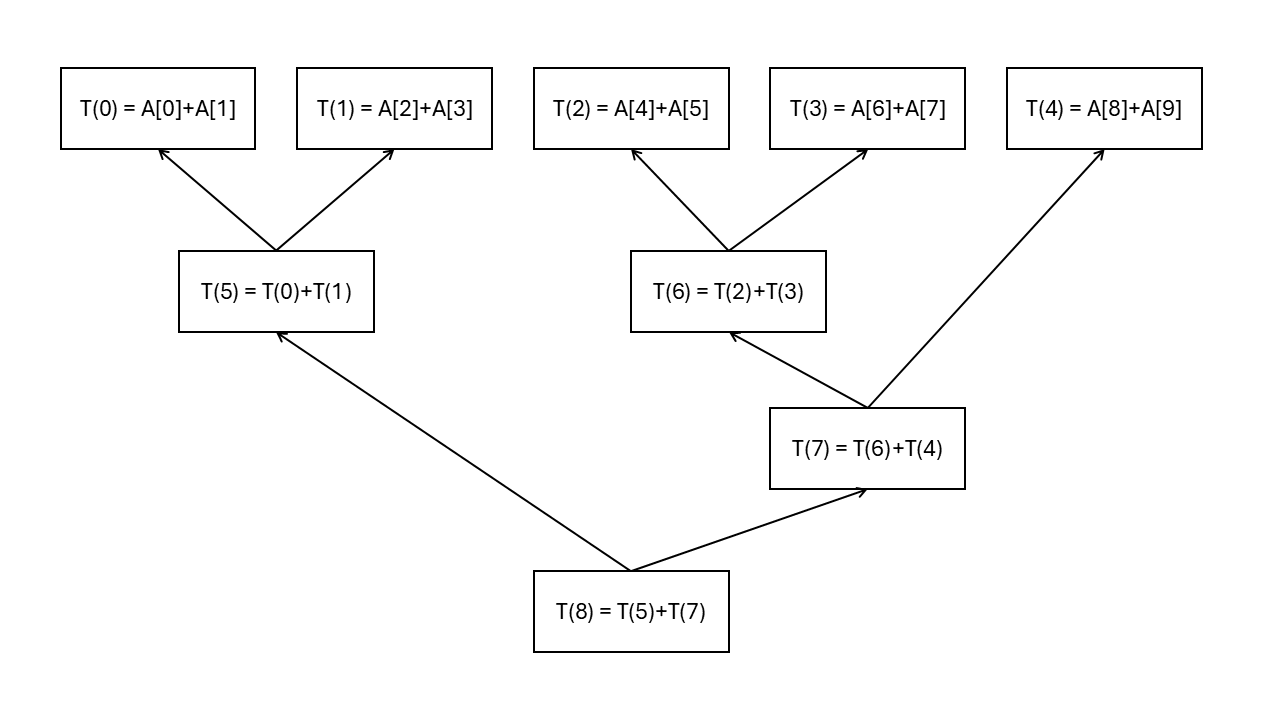
How does this work with a different number of processors? To run the algorithm, we need a scheduler that assigns tasks to processors. The scheduler can work quite simply: it takes tasks in order \(T(0), T(1), \ldots\) and assigns each task to the next available processor. However, a task is scheduled only after all its dependencies are finished. If there are \(N\) processors available, then there is always a processor available for each task. If there are \(m\) processors available, where \(m < N\), then the scheduler assigns the first \(m\) tasks to processors. As soon as any task is finished, it takes the next task and assigns it to the available processor. This way, we don't have to design a parallel algorithm for a specific number of processors. The scheduler maps any algorithm to the available processors.
And that is exactly what async/await frameworks do. They provide a programming language construct to split a procedure, function, or method into small tasks. The framework then implements a scheduler that assigns tasks to available processors, or technically, threads. So the framework provides an abstraction for engineers to write parallel procedures without worrying about the number of available processors.
Historically, processors used to have only a single core. At some point, this changed and multi-core processors became commercially available. There was a need for a framework to bring those multiple cores to software developers without requiring them to know how many cores the target system would have. That was the motivation for creating async/await frameworks.